GLM-5.2 免费体验指南:1M 上下文模型实测 (2026)
GLM-5.2 如何免费体验?在 Mira 注册后可用免费积分在浏览器中直接体验,无需 API key;另附 1M 上下文、编程跑分与第一手科研实测。
想直接免费体验 GLM-5.2,可以在 Mira 注册后用免费积分,在浏览器里调用,无需 API key 或本地配置。
GLM-5.2 于 2026 年 6 月 13 日由 Z.ai(智谱)发布——1M token 上下文、编程优先、MIT 开源,在多项长周期编程基准上以约 GPT-5.5 六分之一的成本胜出。发布后讨论很多,但不少人卡在一个具体问题:怎么免费体验它?
本文先回答这个问题,再用第一手实测拆解它到底强在哪、适合谁。
作者:Mira ·最后更新:2026-06-17
测试方法:本文跑分取自 Z.ai 官方发布与 llm-stats 等第三方公开数据(抓取于 2026-06-17)并交叉核对;产品实测部分见下文「实测案例」。
在哪可以免费体验 GLM-5.2?
在 Mira 免费体验 注册后用免费积分,在浏览器里在线选用 GLM-5.2——开聊或组装 agent,无需 API key、无需写代码、无需配置本地环境。适合想快速看到实际效果,或想把 GLM-5.2 接进真实工作流的人。
其它途径(各有门槛):
| 途径 | 是否要 API key | 是否要写代码 | 上手速度 | 适合谁 |
|---|---|---|---|---|
| Mira 免费积分 | 否 | 否 | 最快 | 想直接用 / 接工作流的人 |
| Z.ai 官方试用额度 | 是 | 是 | 中 | 开发者 |
| 第三方 playground(如 Fireworks、Cloudflare Workers AI) | 视平台 | 部分 | 中 | 想快速测 API 的人 |
| 自托管开源权重 | — | 是 | 慢 | 有 GPU、要数据私有的团队 |
如果你只想零注册、即点即用地随手试模型,Cloudflare Workers AI 这类第三方 playground 最快。Mira 的价值不在“能用上模型”本身,而在把 GLM-5.2 放进科研级 agent 工作流里跑(见下文实测案例)。
GLM-5.2 是什么?(30 秒看懂)
GLM-5.2 是智谱 Z.ai 的最新旗舰模型,定位编程与 agentic(自主任务)场景。
| 项目 | 规格 |
|---|---|
| 发布日期 | 2026 年 6 月 13 日 |
| 架构 | Mixture-of-Experts(MoE),744B 总参数 / 40B 激活 |
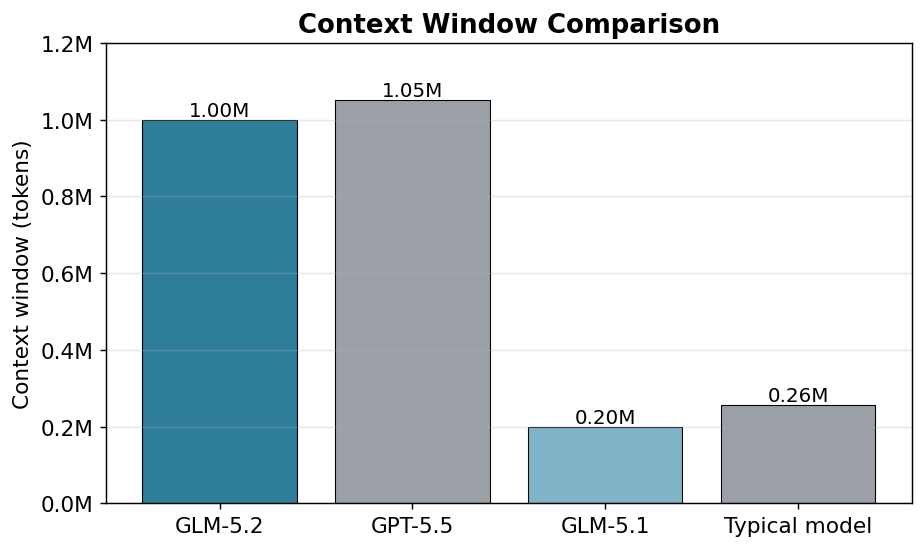
| 上下文窗口 | 1,000,000 token(约为 GLM-5.1 的 5 倍) |
| 最大输出 | 131,072 token |
| 许可证 | MIT(可免费商用、可自托管) |
| 开源权重 | Hugging Face zai-org/GLM-5.2 |
| 首日支持的 agent | Claude Code、Cline、OpenCode、OpenClaw、Goose、Crush、Kilo |
一句话:一个 MIT 许可、可商用的模型,具备 1M token 上下文,编程基准分数可与头部闭源模型竞争。
GLM-5.2 核心能力
1. 1M token 超长上下文
GLM-5.2 能一次吞下约 100 万 token——整个中型代码库、几百页文档、一整轮长对话历史都能塞进去,不用切片。这是它相对上一代最大的跳跃(GLM-5.1 约 200K)。
2. 编程能力进开源第一梯队
标准编程基准 SWE-bench Pro 上,GLM-5.2 拿到 62.1,高于 GPT-5.5 的 58.6(数据见 llm-stats);终端与工具调用基准 Terminal-Bench 2.1 得 81.0。在长周期(多步、跨文件)编程任务上,它也是目前得分最高的开源模型之一。完整跑分见下文「实测评测与跑分」。
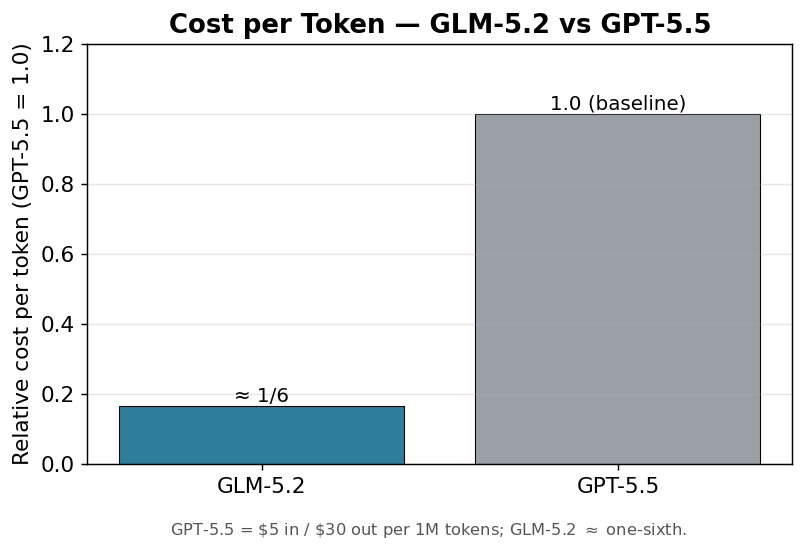
3. 约 1/6 的成本
对标 GPT-5.5(输入 $5 / 输出 $30 每百万 token,见 OpenAI GPT-5.5 发布页)的同类任务,GLM-5.2 每 token 成本约为其六分之一。长任务、批量 agent 场景下,这个成本差距会持续积累,影响可观。
4. MIT 开源,可商用、可自托管
权重已上 Hugging Face,MIT 许可——商用、改造、私有部署几乎零限制。对数据敏感的团队是关键。
5. 首日 agent 生态
发布当天即获 Claude Code、Cline、OpenCode、OpenClaw、Goose、Crush、Kilo 等主流编码 agent 支持——接入现有工作流几乎零等待。Mira 也在发布当周接入了 GLM-5.2,本文「实测案例」即在其上运行。
GLM-5.2 实测评测与跑分
跑分取自 Z.ai 官方发布与第三方公开数据交叉核对,来源:VentureBeat、llm-stats、CryptoBriefing(抓取于 2026-06-17,数字可能随官方更新):
| 基准 | GLM-5.2 得分 | 类型 |
|---|---|---|
| SWE-bench Pro | 62.1 | 标准编程 |
| Terminal-Bench 2.1 | 81.0 | 终端/工具调用 |
| FrontierSWE | 74.4% | 长周期编程 |
| PostTrainBench | 34.3% | 长周期 |
| SWE-Marathon | 13.0% | 长周期 |
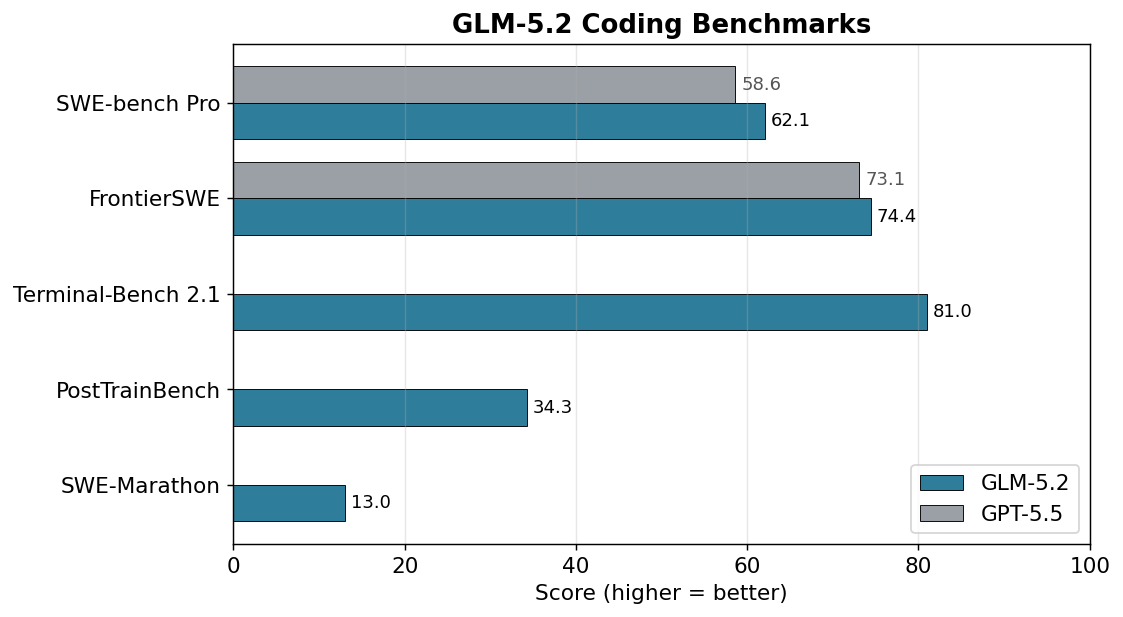
怎么读: GLM-5.2 在标准编程基准上是最强开源模型;长周期(多步、跨文件)任务上也是开源里最高。短板在极端长周期(SWE-Marathon 13.0%)——超长自主任务仍有提升空间,这点下文「适合谁,不适合谁」一节里会诚实说。
GLM-5.2 vs GPT-5.5:成本与编程
| 维度 | GLM-5.2 | GPT-5.5 |
|---|---|---|
| SWE-bench Pro | 62.1 | 58.6 |
| FrontierSWE(长周期) | 74.4% | 73.1%(Expert-SWE) |
| 上下文 | 1,000,000 | 1,050,000 |
| 价格(每百万 token) | 约为 GPT-5.5 的 1/6 | 输入 $5 / 输出 $30 |
| 开源 / 自托管 | ✅ MIT | ❌ |
| 生态成熟度 | 新,但扩张快 | 成熟 |
数据来源:GPT-5.5 规格与价格 ·GLM-5.2 跑分。注意:两者上下文都在 1M 量级,GPT-5.5(1.05M)略大——GLM-5.2 的核心差异在成本与开源可自托管,而非上下文长度。
此对比引用公开报道的 GPT-5.5 数据;本文实测案例用的是平台当前提供的 GPT-5.4。
结论: 编程与 agentic 任务、尤其当 token 成本是约束时,GLM-5.2 是很有竞争力的选择;追求最成熟通用生态与全能性,GPT-5.5 仍有其位置。
实测案例:用 GLM-5.2 跑一个真实科研任务
我们在 Mira 上做了一次真实对比:同一个项目、同一个问题,分别用 GLM-5.2 和 GPT-5.4 驱动同一个科研 agent,看它们在真实 R&D 任务上的表现。
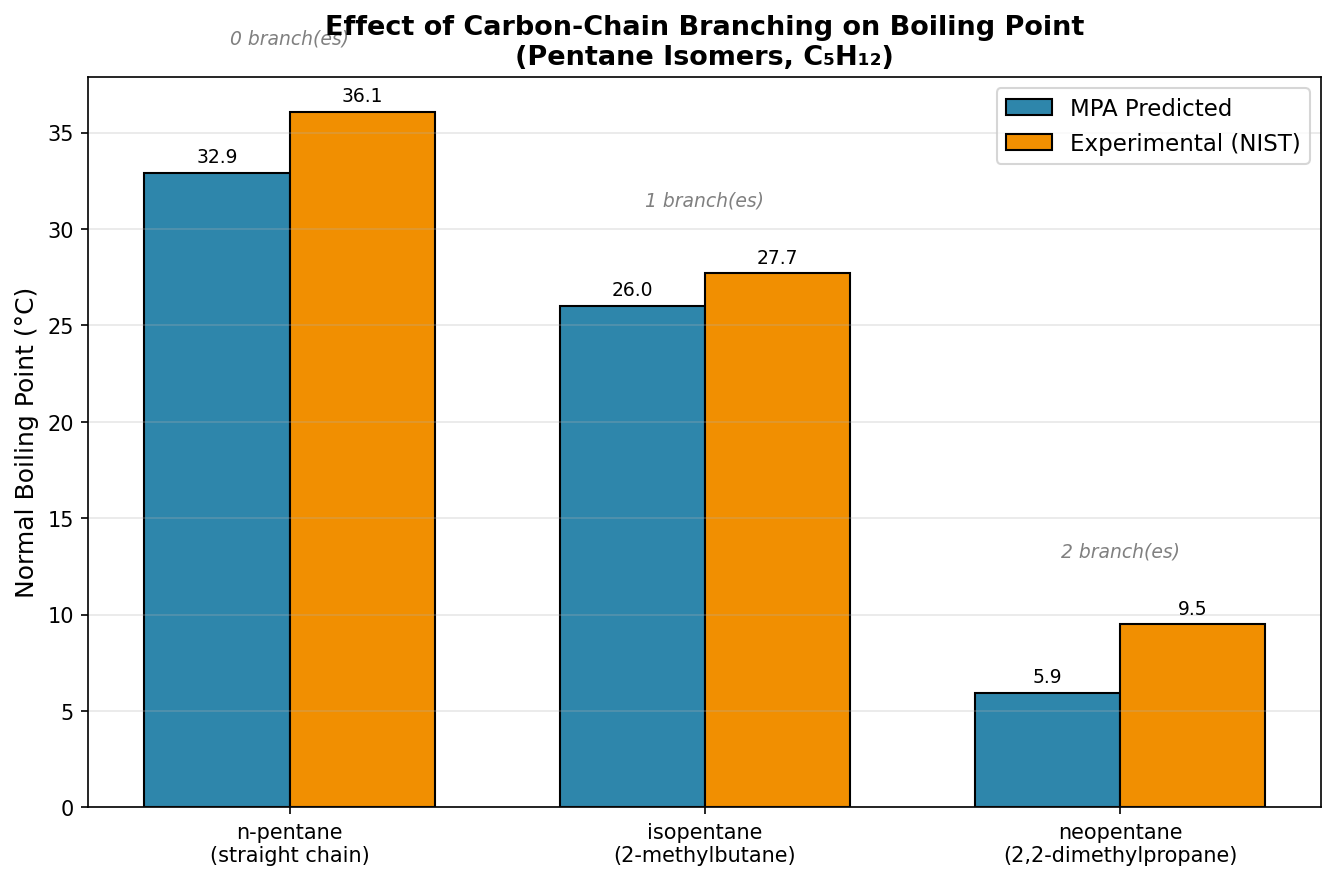
任务: 预测三种戊烷异构体(正戊烷、异戊烷、新戊烷)的沸点,并分析支链对沸点的影响——通过 /material-property-prediction(MPA 模型)技能完成。
一个诚实前提: 两个 session 调用的是同一个 MPA 预测后端,所以核心预测数值完全相同(见下表)。这次比的不是"谁算得准",而是模型作为 agent 的驱动质量——会不会主动验证、可视化、把结果讲清楚。
预测 vs NIST 实验值(两模型一致):
| 异构体 | 支链数 | 预测沸点 (°C) | 实验值 NIST (°C) | 误差 |
|---|---|---|---|---|
| 正戊烷 | 0 | 32.9 | 36.1 | −3.2 |
| 异戊烷 | 1 | 26.0 | 27.7 | −1.7 |
| 新戊烷 | 2 | 6.0 | 9.5 | −3.6 |
随支链增多沸点单调下降;正戊烷→新戊烷总降幅预测 −27.0 °C vs 实验 −26.6 °C(误差 0.4 °C 内)。
差异在"怎么完成任务":
| 指标 | GLM-5.2 | GPT-5.4 |
|---|---|---|
| 轮次 | 7 | 11 |
| 输入 token | 168,613 | 222,843 |
| 输出 token | 3,971 | 1,350 |
| 耗时 | 118.3s | 134.1s |
| 主动对比 NIST 实验值 | ✅ | ❌ |
| 生成对比图表 | ✅ | ❌ |
| 物理机理解释 | 详细 | 简短 |
- GLM-5.2 主动把预测值与 NIST 实验值逐项对比、算出误差、生成对比柱状图,并解释了物理机理(支链使分子趋于球形、接触面积非线性下降、削弱伦敦色散力)。同时用了更少轮次、更少输入 token、更快完成。
- GPT-5.4 给出了正确的预测值和简短的支链说明,但没有对比实验值、没有生成图表,产出更精简。
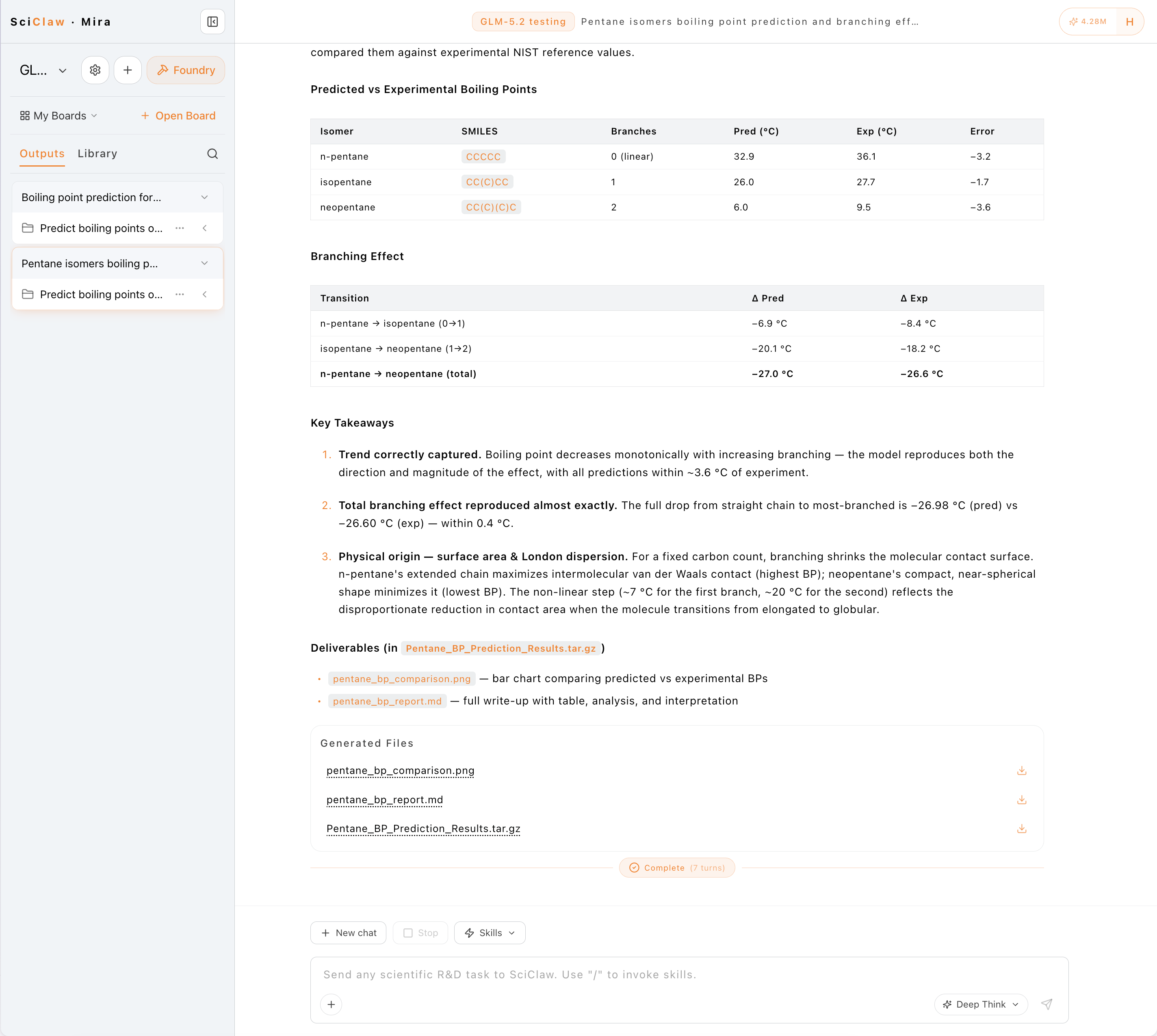
结论(限定范围): 在这个单次科研任务里,GLM-5.2 作为 agent 驱动更主动、更完整,且更省 token——叠加约 1/6 的成本,对批量科研工作流很有吸引力。需说明:这是 N=1 的单次观察,不是系统基准;此处对比的是平台上可用的 GPT-5.4,与前文跑分中的 GPT-5.5 并非同一版本。
如果你关心的不只是模型本身的能力,还想了解 AI 如何参与完整科研流程,可以继续阅读:Claude Science vs Mira:从 AI 科研工作台到 AI Scientist Platform。
想自己复现?在 Mira 用免费积分跑同样的任务。开始使用 →
GLM-5.2 适合谁,不适合谁
适合:
- 编程 / agentic 工作流,尤其在意 token 成本
- 需要一次处理超长上下文(大代码库、长文档、科研材料)
- 要数据私有、需自托管的团队(MIT 权重)
暂不适合 / 需注意:
- 极端长周期自主任务仍有短板(SWE-Marathon 13.0%)
- 部分第三方独立基准仍在陆续公布,数字可能更新
- 追求最成熟通用生态的场景,闭源旗舰仍有优势
常见问题(FAQ)
Q:GLM-5.2 可以免费体验吗? 模型本身 MIT 开源、免费可商用。云端调用上,Mira 提供免费积分让你零配置直接用;Z.ai 等平台另有试用额度。
Q:用 GLM-5.2 一定要 API key 吗? 不一定。在 Mira 里用免费积分即可,无需 API key、无需写代码。自己直连官方 API 才需要 key。
Q:GLM-5.2 能商用吗? 能。MIT 许可允许商用、修改、私有部署。
Q:GLM-5.2 的上下文有多大? 最高 1,000,000 token,约为上一代的 5 倍。
Q:GLM-5.2 比 GPT-5.5 强吗? 在多项长周期编程基准上胜出,且成本约为 1/6;通用生态成熟度上 GPT-5.5 仍有优势。
Q:GLM-5.2 编程跑分如何? SWE-bench Pro 62.1、Terminal-Bench 2.1 81.0、FrontierSWE 74.4%——开源第一梯队。
Q:可以本地运行 GLM-5.2 吗?
可以,权重在 Hugging Face(zai-org/GLM-5.2),需自备 GPU。详见本地部署专文。
Q:在哪可以免费体验 GLM-5.2? Mira,注册送积分,浏览器即开即用。
想自己上手验证? 在 Mira 用免费积分调用 GLM-5.2,无需 key 或配置,可直接接入 agent 试跑上面的场景。开始使用 →